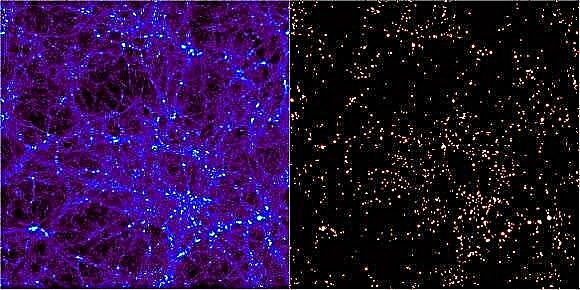
宇宙のΛCDMモデルの成功の1つは、スペースマガジンに表示されるのと同様のスケールと分布でモデルを構造化する機能です。コンピュータシミュレーションはボックス内の数値宇宙を再現することができますが、これらの数学的近似を解釈すること自体が困難です。シミュレーションされた空間のコンポーネントを特定するために、天文学者は構造を検索するためのツールを開発する必要がありました。結果は1974年以来、ほぼ30の独立したコンピュータプログラムでした。それぞれは、暗黒物質ハローが形成される領域を見つけることによって、宇宙の形成構造を明らかにすることを約束します。これらのアルゴリズムをテストするために、2010年5月にスペインのマドリードで「Haloes going MAD」と題された会議が開催されました。
有名なミレニアムシミュレーションのような宇宙の数値シミュレーションは、「粒子」以外の何物でも始まりません。これらは宇宙論のスケールでは間違いなく小さいものでしたが、そのような粒子は数百万または数十億の太陽質量を伴う暗黒物質の塊を表しています。時間が進むにつれて、物理学およびそのような物質の性質についての私たちの最良の理解と一致する規則に従って、それらは互いに相互作用することが許可されます。これは進化する宇宙につながり、そこから天文学者は複雑なコードを使用して、銀河が形成されるであろう暗黒物質の集まりを見つける必要があります。
このようなプログラムが使用する主な方法の1つは、小さな過密度を検索し、密度が無視できる程度に低下するまでその周りに球殻を成長させることです。その後、ほとんどの場合、重力に拘束されていないボリューム内の粒子をプルーニングして、時間の経過とともにばらばらになる短い一時的なクラスタリングで検出メカニズムが捕捉されないようにします。他の手法では、他の位相空間を検索して、すべての近くで同様の速度を持つ粒子を探します(それらが束縛されていることを示す兆候)。
各アルゴリズムがどのように進んだかを比較するために、2つのテストが行われました。 1つ目は、サブハローが埋め込まれた意図的に作成された一連のダークマターハローが含まれていました。粒子分布は意図的に配置されているため、プログラムからの出力はハローの中心とサイズを正しく検出するはずです。 2番目のテストは、本格的な宇宙シミュレーションです。この場合、実際の分布はわかりませんが、その純粋なサイズにより、異なるプログラムを同じデータセットで比較して、共通のソースをどのように解釈したかを確認できます。
どちらのテストでも、すべてのファインダーは一般的にうまく機能しました。最初のテストでは、さまざまなプログラムがハローの位置をどのように定義したかに基づいて、いくつかの不一致がありました。密度のピークとして定義する人もいれば、重心として定義する人もいます。サブハローを検索するとき、フェーズスペースアプローチを使用したハローは、より小さな構成をより確実に検出できるように見えましたが、クランプ内のどの粒子が実際にバインドされているかを常に検出できるとは限りませんでした。完全なシミュレーションでは、すべてのアルゴリズムが非常によく一致しました。シミュレーションの性質上、小さなスケールは十分に表現されていなかったため、それぞれがこれらの構造を検出する方法についての理解は限られていました。
これらのテストの組み合わせは、特定のアルゴリズムやメソッドを他のものよりも優先しませんでした。それは、それぞれが一般にお互いに関してうまく機能することを明らかにしました。非常に多くの独立したコードと独立した方法の能力は、調査結果が非常に堅牢であることを意味します。宇宙に関する私たちの理解がどのように進化するかについて彼らが受け継いだ知識により、天文学者は、そのようなモデルや理論をテストするために、観測可能な宇宙との基本的な比較を行うことができます。
このテストの結果は、Royal Astronomical Societyの毎月の通知の次の号で公開される予定の論文にまとめられました。